使用指南 — How to Use This Site
冯老师您好! 这个网站是专门为您准备的论文审阅平台,以下是各功能的使用方法:
① 查看论文
向下滚动到「论文在线阅读」板块,点击「中文版」或「English」切换。论文全文直接以网页形式展示,可以直接选中文字进行批注。也可以在下方「Downloads」部分下载 PDF、Word 或 LaTeX 源文件。
② 论文批注(直接在论文文字上操作)
在「论文在线阅读」区域,论文全文以网页形式展示,您可以直接选中任意论文文字 → 弹出操作面板:
• ✏️ 需要修改 → 文字变红底红色下划线
• 💎 润色 → 文字变蓝底蓝色虚线下划线
• 🗑️ 建议删除 → 文字变灰色删除线
• 💬 自定义批注 → 紫色点状下划线,可输入具体意见
• 每次操作自动保存到留言板 + 微信推送通知给我
③ 提交留言
向下滚动到「导师留言板」,选择类型(新想法/修改建议/提问),输入内容后点击「提交」即可。我会立即收到微信推送通知。
研究概述 — Research Overview
研究问题:在加密流量分类任务中,恶意样本标注数量少且成本高,预训练模型(如 ET-BERT)在少样本场景下性能严重退化。如何在标注极度稀缺的条件下实现高精度的加密流量分类?
为什么重要:加密流量已占互联网总流量的绝大部分,传统 DPI 已失效;同时新型攻击变种不断涌现,每类只有极少标注样本。这导致现有深度模型在少样本条件下决策边界不稳定,泛化能力不足。本文发现的核心规律——“检索增强的收益与预训练表征的覆盖缺口成正比”——为实际部署提供了可操作的运用指导。
我们怎么做的:提出 RAC-ET(Retrieval-Augmented Classification for Encrypted Traffic)框架,核心思路是“参数化知识 + 非参数化记忆”的协同:冻结 ET-BERT 提取流量深层语义特征,构建 FAISS 向量知识库存储历史样本,推理时检索 Top-K 相似样本,通过交叉注意力机制自适应融合查询特征与检索特征,仅训练 3.69% 的参数即可显著提升性能。
核心发现:
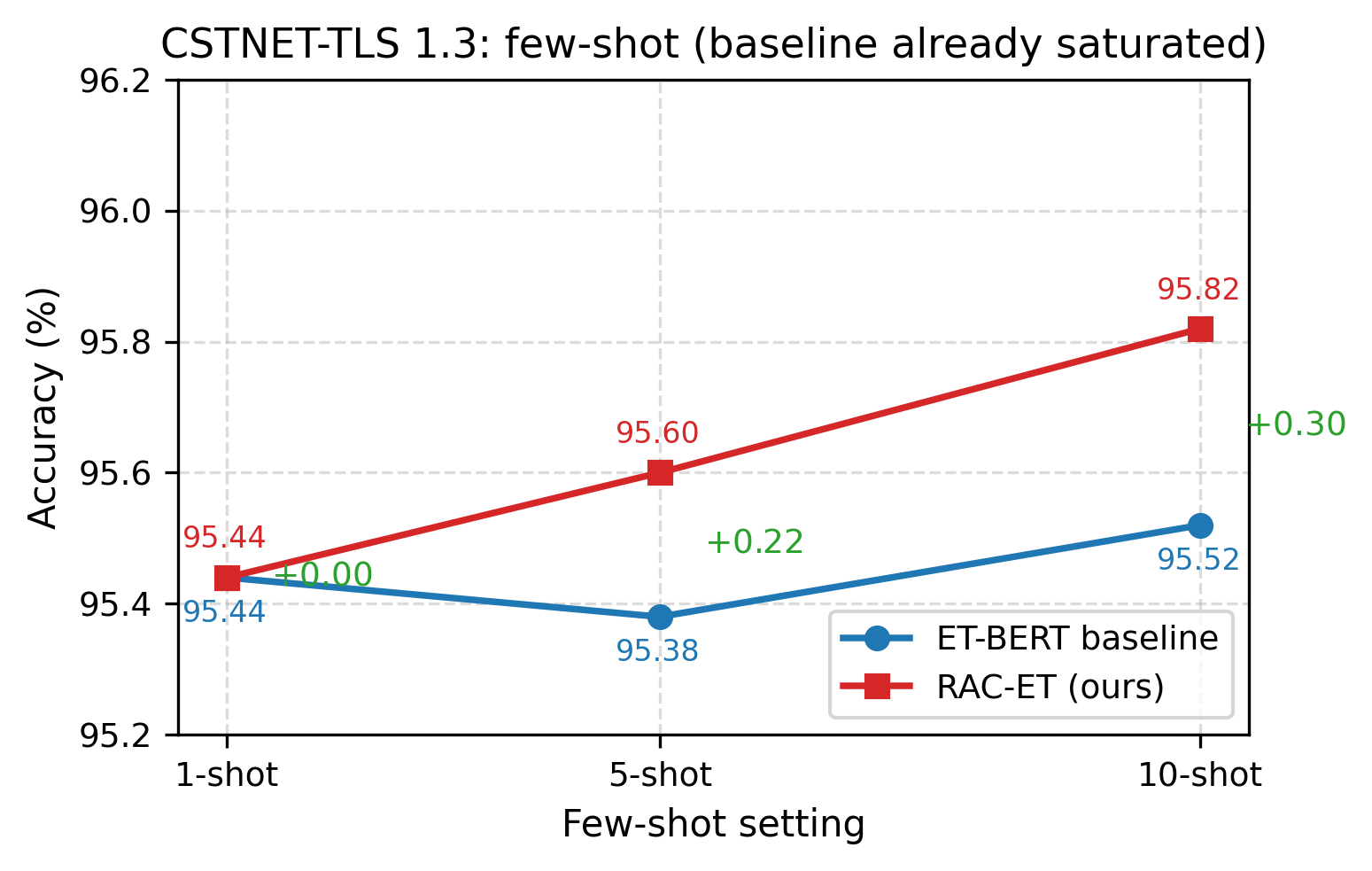
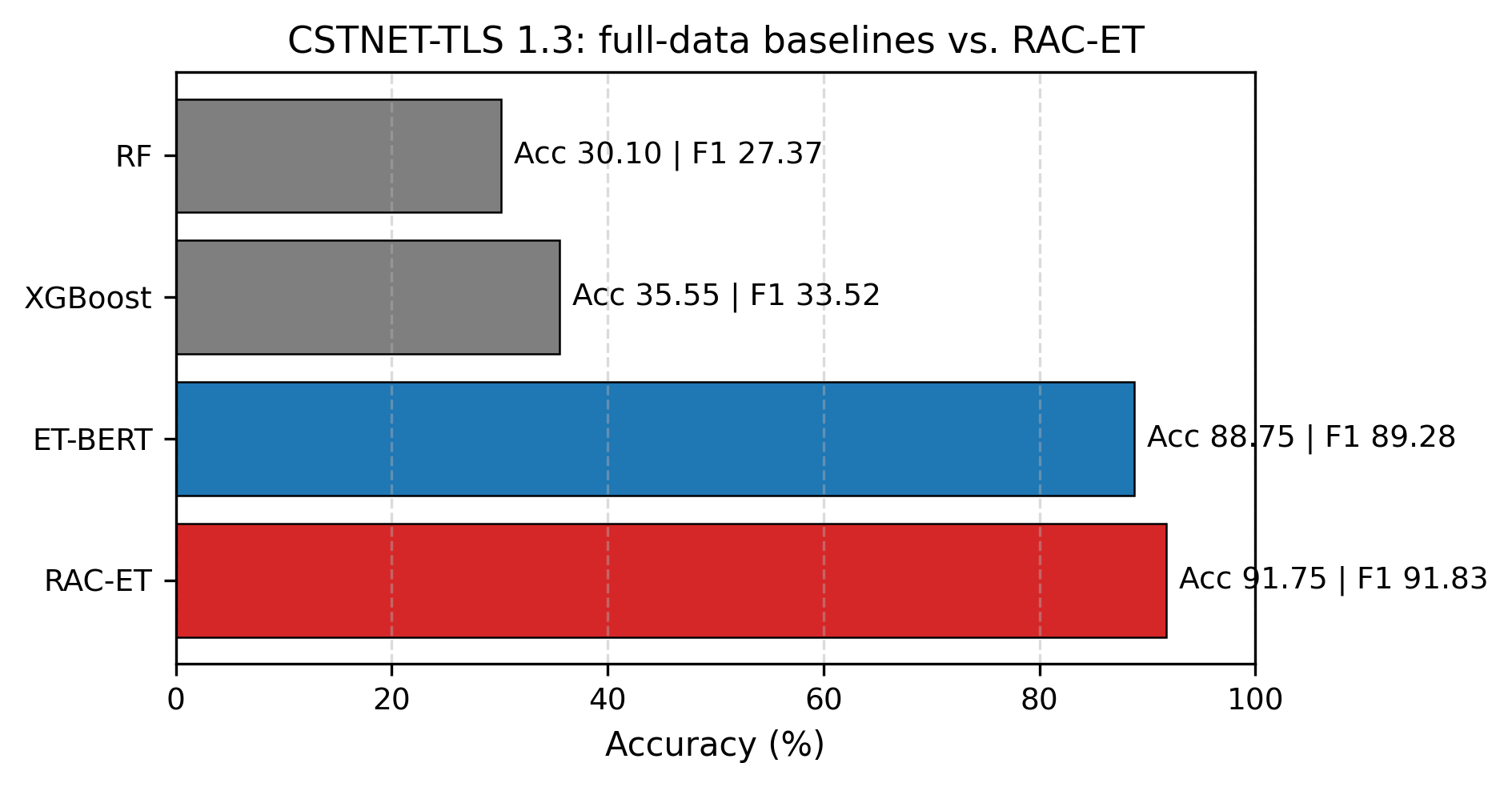
- CSTNET-TLS 1.3(120 类,ET-BERT 预训练覆盖充分):少样本 +0.30%,全量数据 +3.00%(88.75%→91.75%)
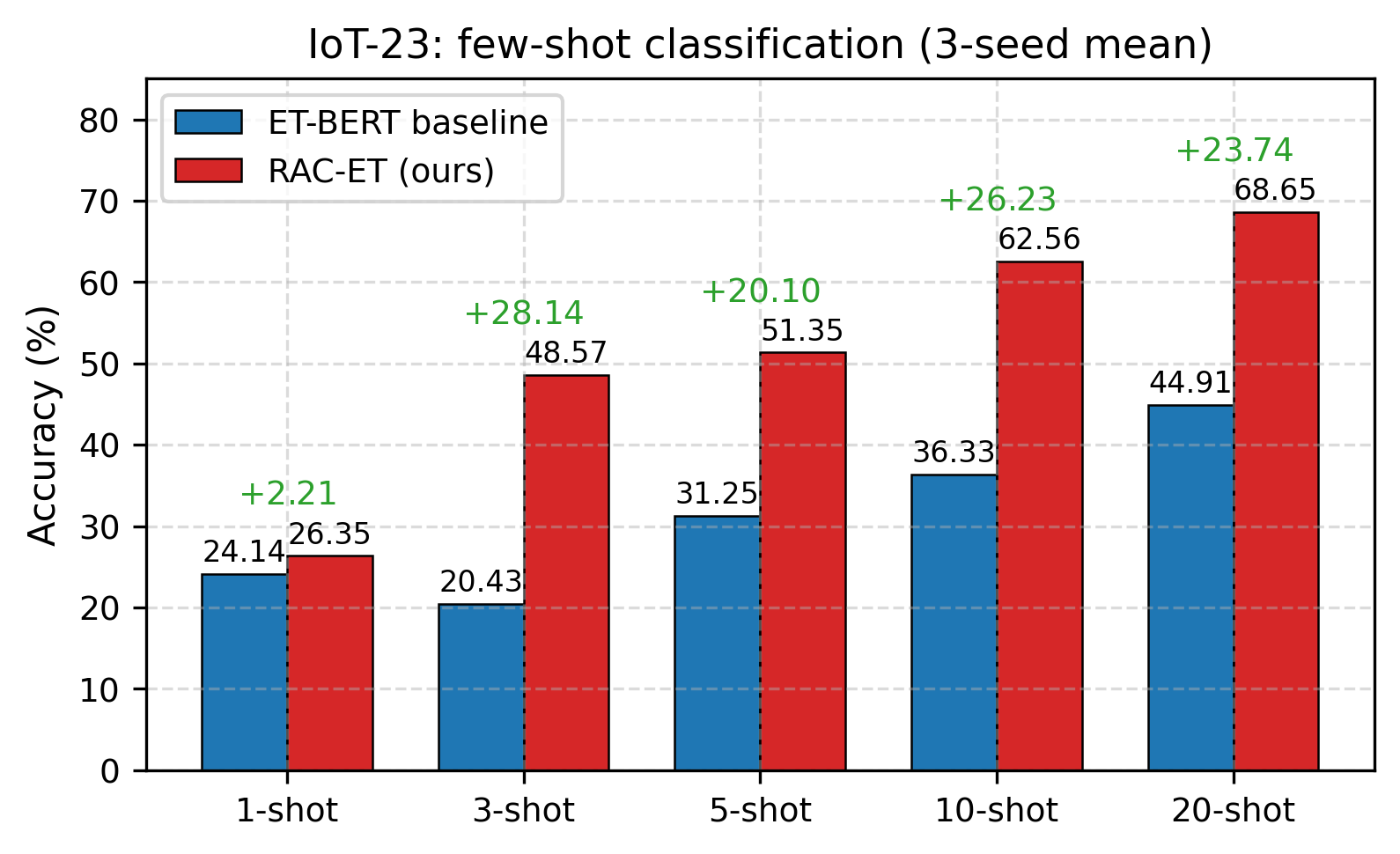
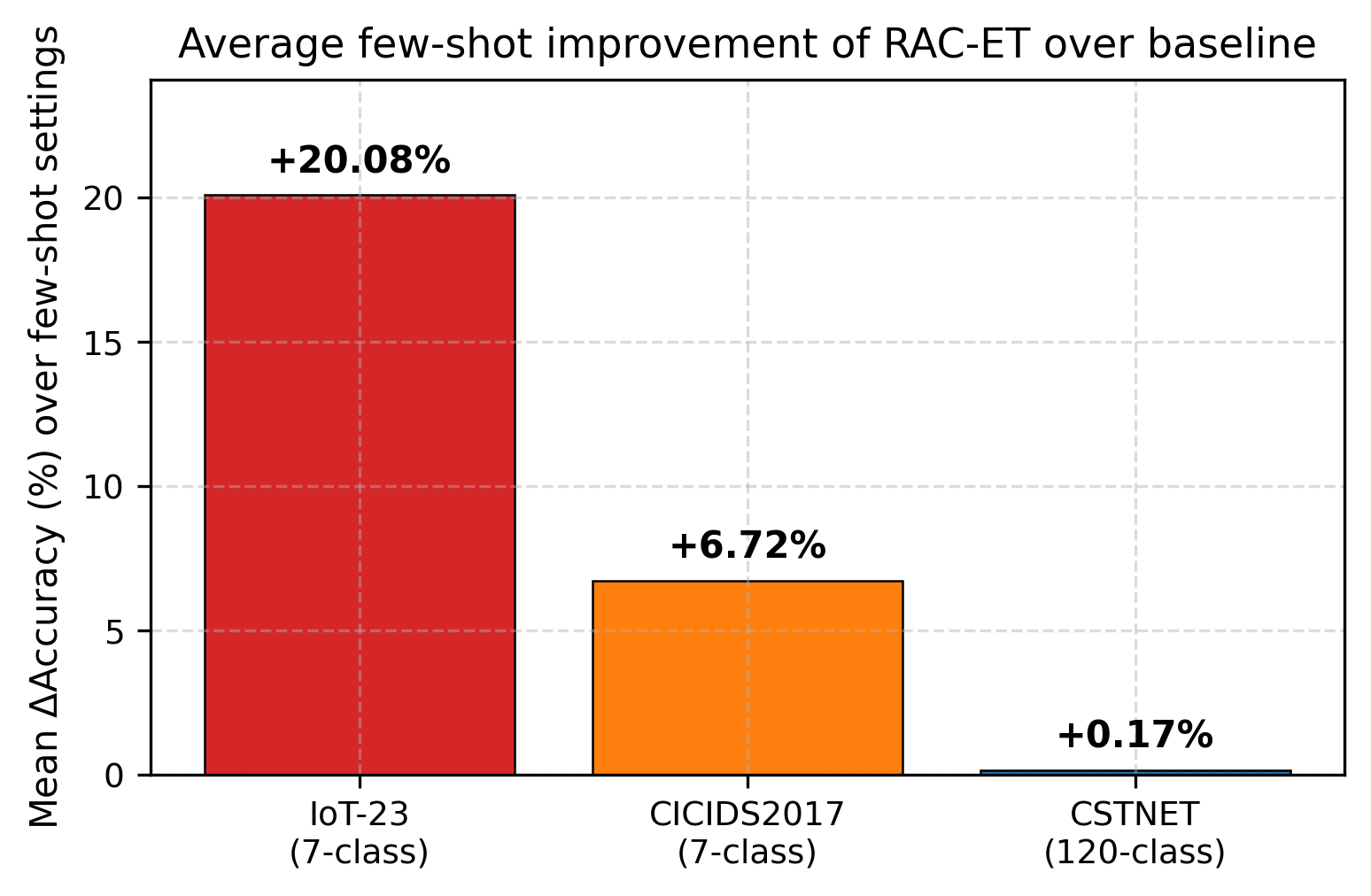
- IoT-23(7 类,分布偏移大):平均 +20.09%,3-shot 最大 +28.15%
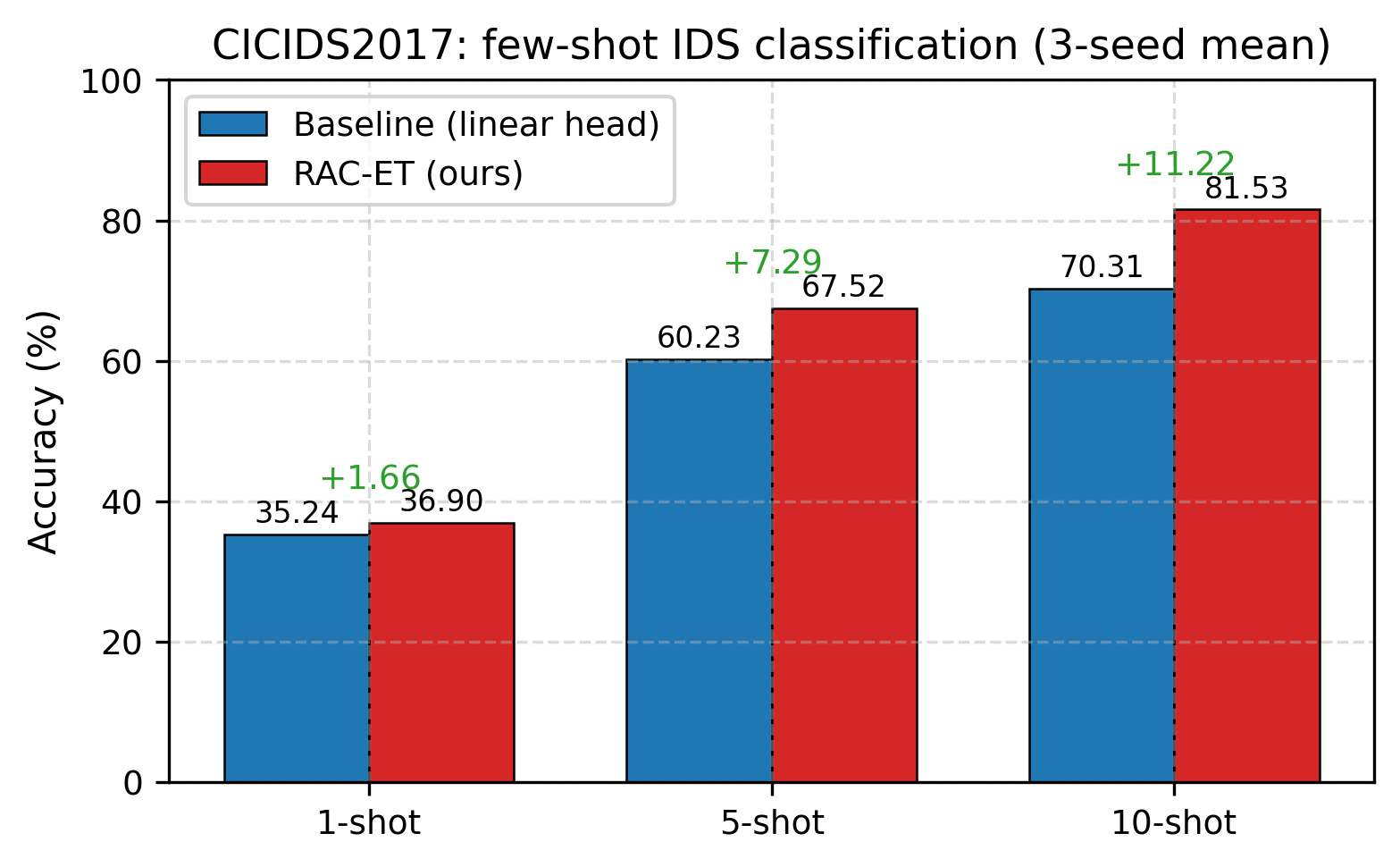
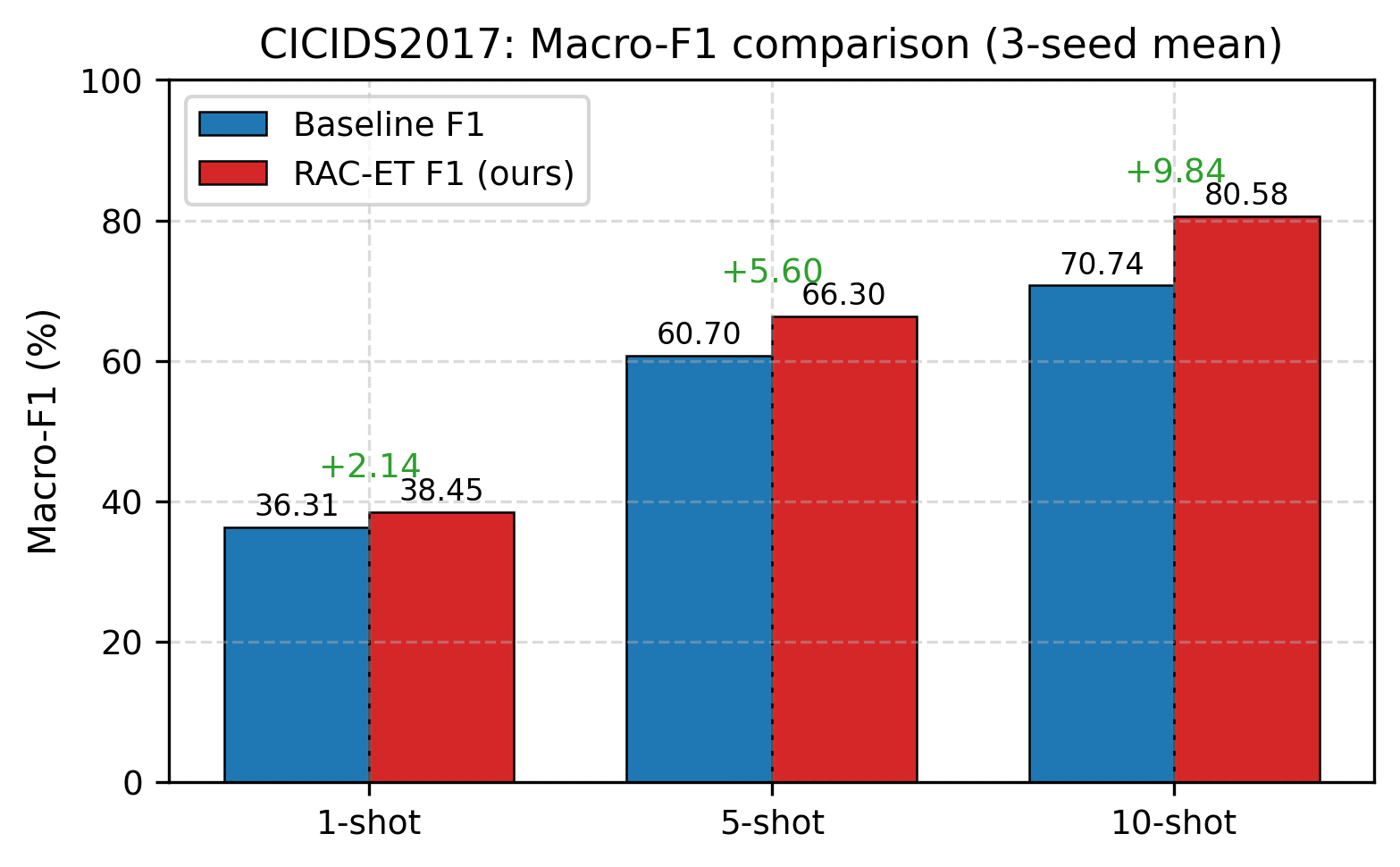
- CICIDS2017(7 类,流统计特征输入):10-shot +11.22%,验证跨模态泛化
关键规律:预训练表征覆盖缺口越大,检索增强的收益越显著。
主要贡献:
- (1) 首次将检索增强分类系统性地引入加密流量少样本分类,并在多数据集、多模态上验证有效性
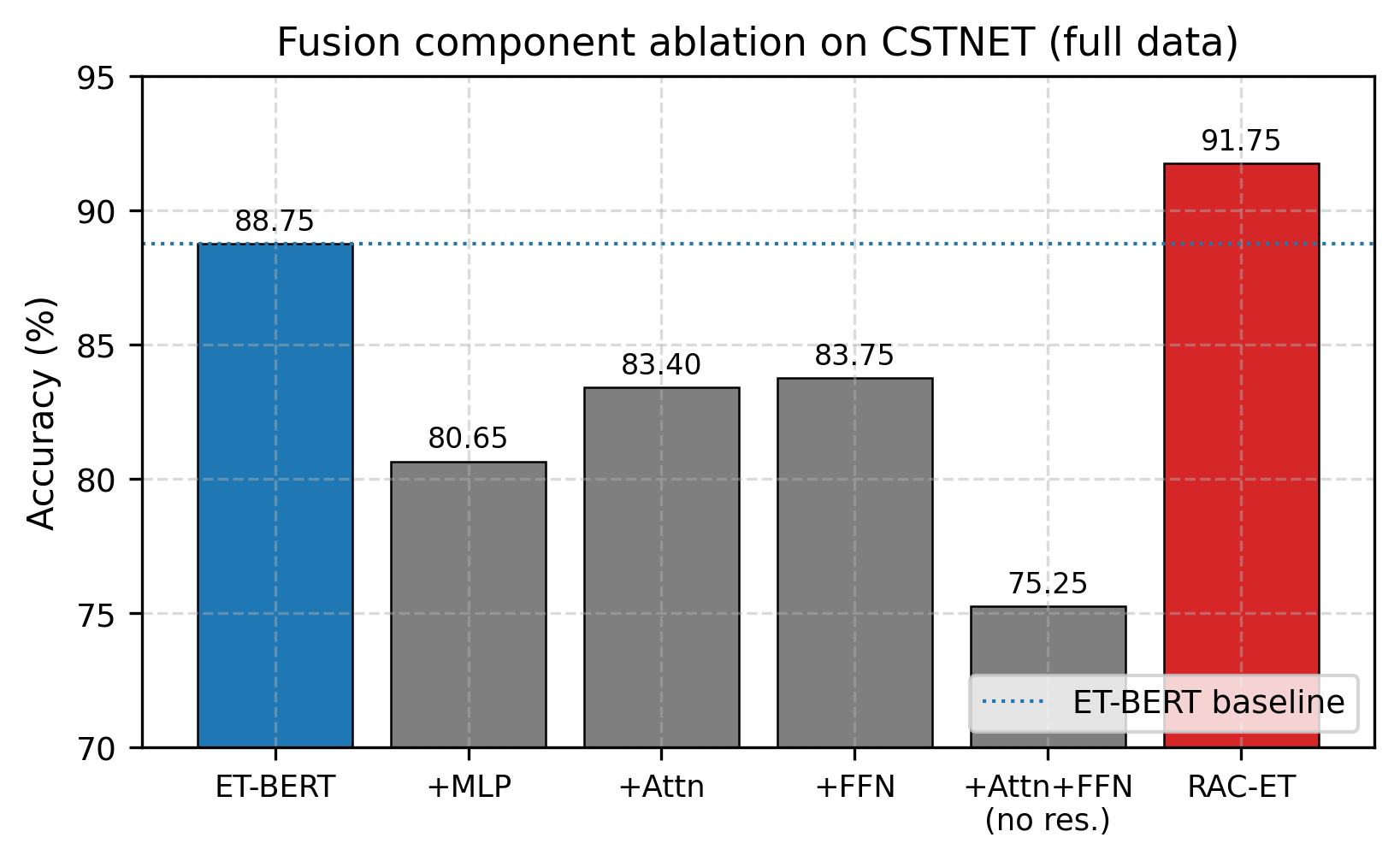
- (2) 设计交叉注意力融合机制,消融实验证明其在抑制检索噪声方面不可替代
- (*) 知识库支持动态更新:新攻击样本即插即用,无需重训任何模型参数,满足实时部署需求
Key Results
| Dataset | Classes | Setting | Baseline | RAC-ET | Improvement |
|---|---|---|---|---|---|
| CSTNET-TLS 1.3 | 120 | 1-shot | 95.44% | 95.44% | +0.00% |
| 5-shot | 95.38% | 95.60% | +0.22% | ||
| 10-shot | 95.52% | 95.82% | +0.30% | ||
| IoT-23 | 7 | 1-shot | 24.14% | 26.35% | +2.21% |
| 3-shot | 20.43% | 48.57% | +28.15% | ||
| 5-shot | 31.25% | 51.35% | +20.11% | ||
| 10-shot | 36.33% | 62.56% | +26.23% | ||
| 20-shot | 44.91% | 68.65% | +23.73% | ||
| CICIDS2017 | 7 | 1-shot | 35.24% | 36.90% | +1.66% |
| 5-shot | 60.23% | 67.52% | +7.29% | ||
| 10-shot | 70.31% | 81.53% | +11.22% | ||
| Dataset | Setting | Baseline F1 | RAC-ET F1 | ΔF1 |
|---|---|---|---|---|
| CSTNET-TLS 1.3 | 1-shot | 95.44% | 95.44% | +0.00% |
| 5-shot | 95.38% | 95.60% | +0.22% | |
| 10-shot | 95.52% | 95.82% | +0.30% | |
| CICIDS2017 | 1-shot | 36.31% | 38.45% | +2.14% |
| 5-shot | 60.70% | 66.30% | +5.60% | |
| 10-shot | 70.74% | 80.58% | +9.84% | |
Architecture
Input traffic → ET-BERT (frozen) → Query Feature (768-dim) → FAISS Top-K Retrieval → Cross-Attention Fusion + FFN + Residual → Classification Head → Prediction. Only 3.69% of parameters are trainable (5.07M / 137.3M).
Experiment Figures
导师专栏 — Update Log
本次更新摘要 (2026-04-22)
1. 实验部分
• 三个数据集完整实验:CSTNET-TLS 1.3(应用识别,120 类)、IoT-23(IoT 恶意软件家族,7 类)、CICIDS2017(网络入侵检测,7 类)
• 少样本设定:1-shot、3-shot、5-shot、10-shot、20-shot,覆盖极端标注稀缺到中等标注量
• 核心结果:IoT-23 平均提升 +20.09%(3-shot 最大 +28.15%);CICIDS2017 10-shot +11.22%;CSTNET 全量 +3.00%
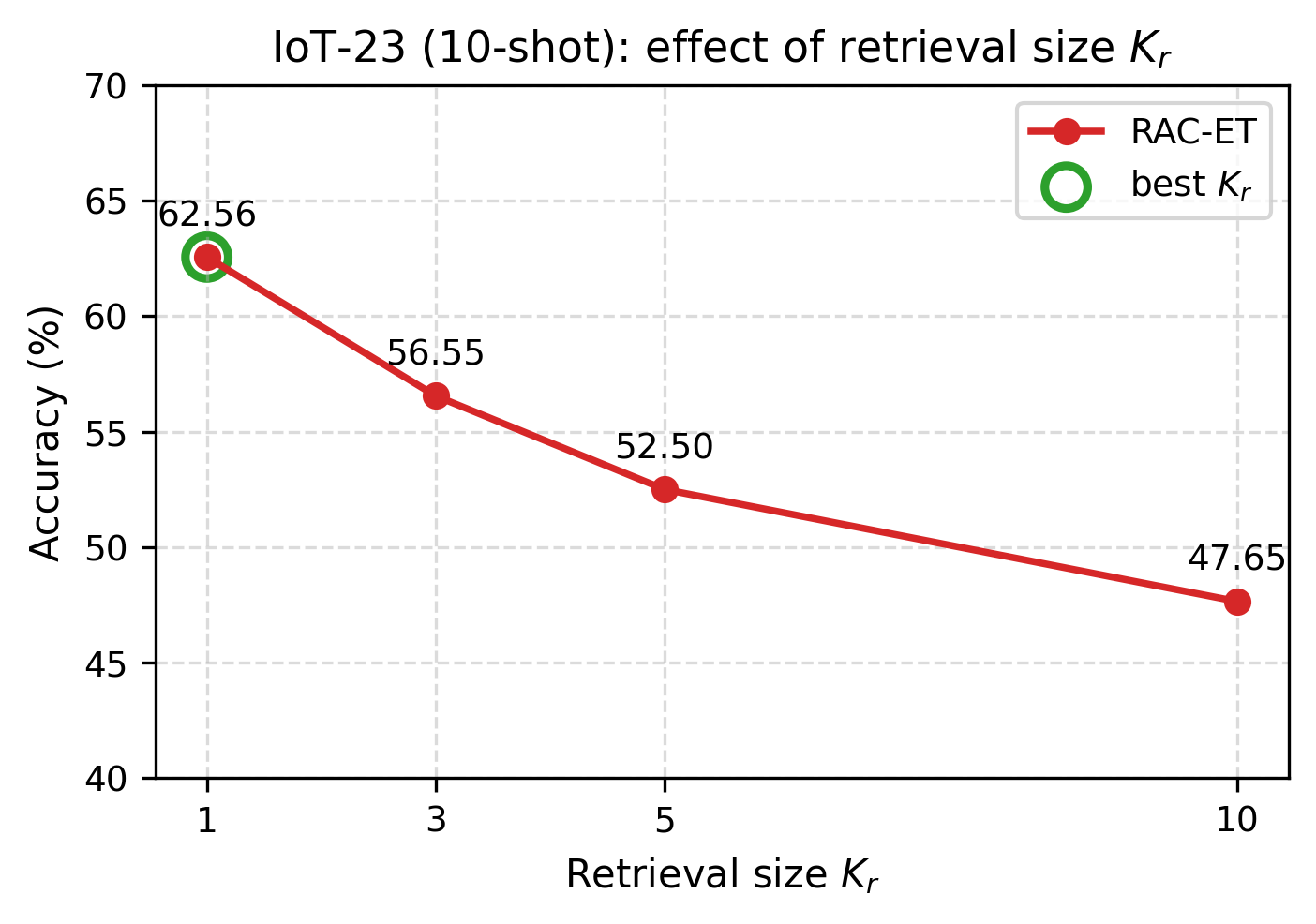
• 消融实验:验证交叉注意力融合不可替代(去掉后性能大幅下降),Kr=5 效果最优
• 效率分析:仅训练 3.69% 参数(5.07M/137.3M),推理延迟增加 <5ms
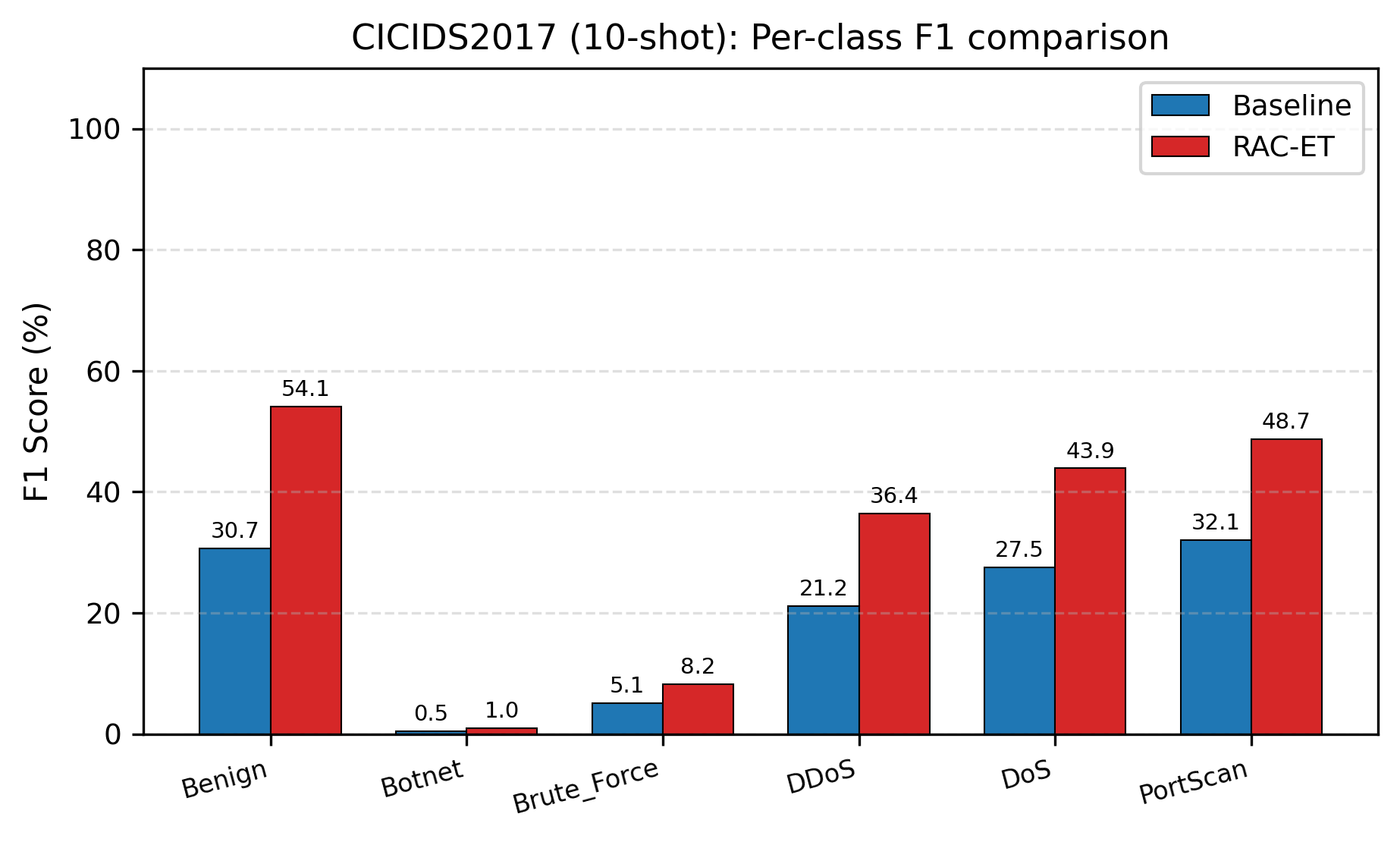
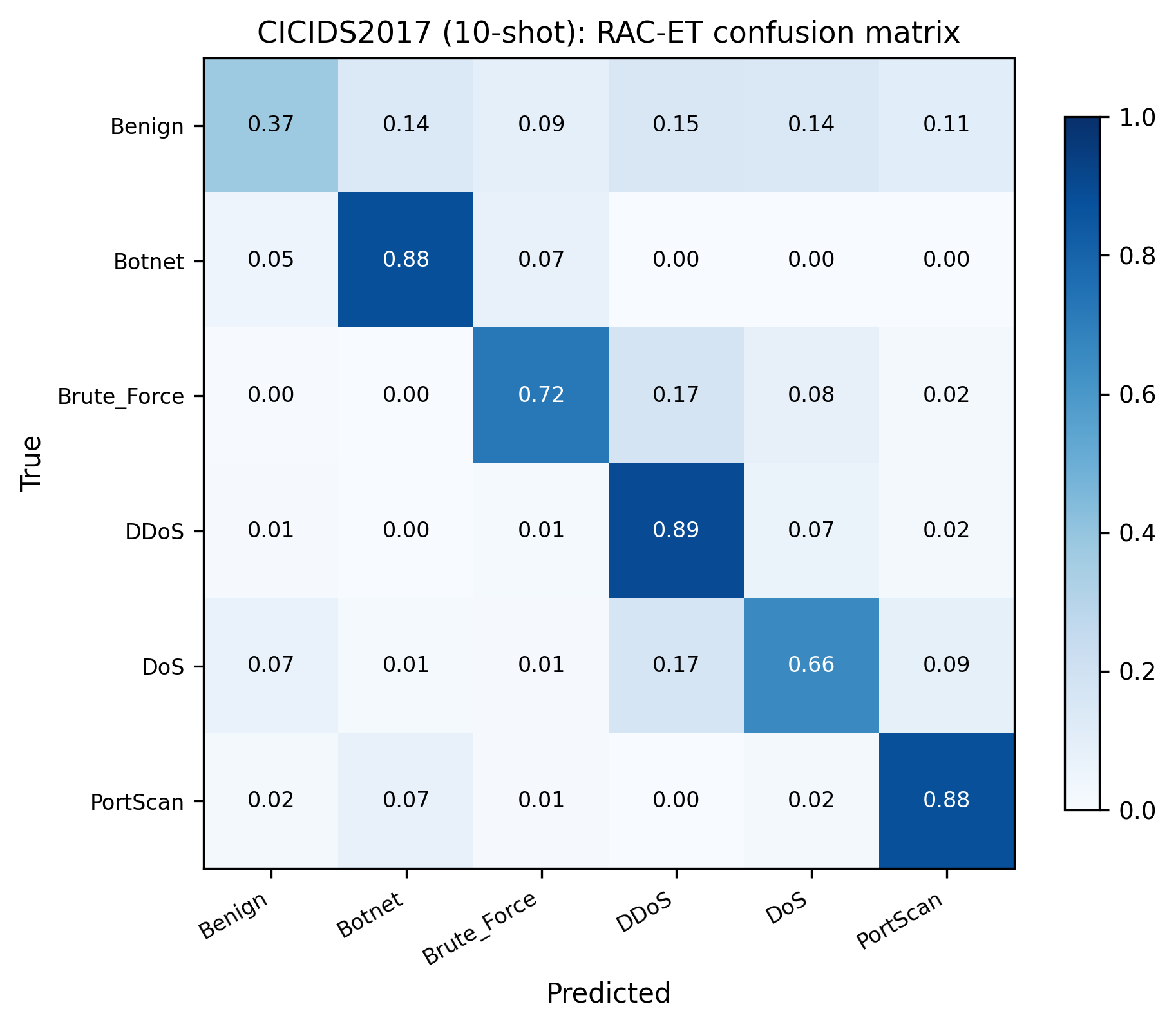
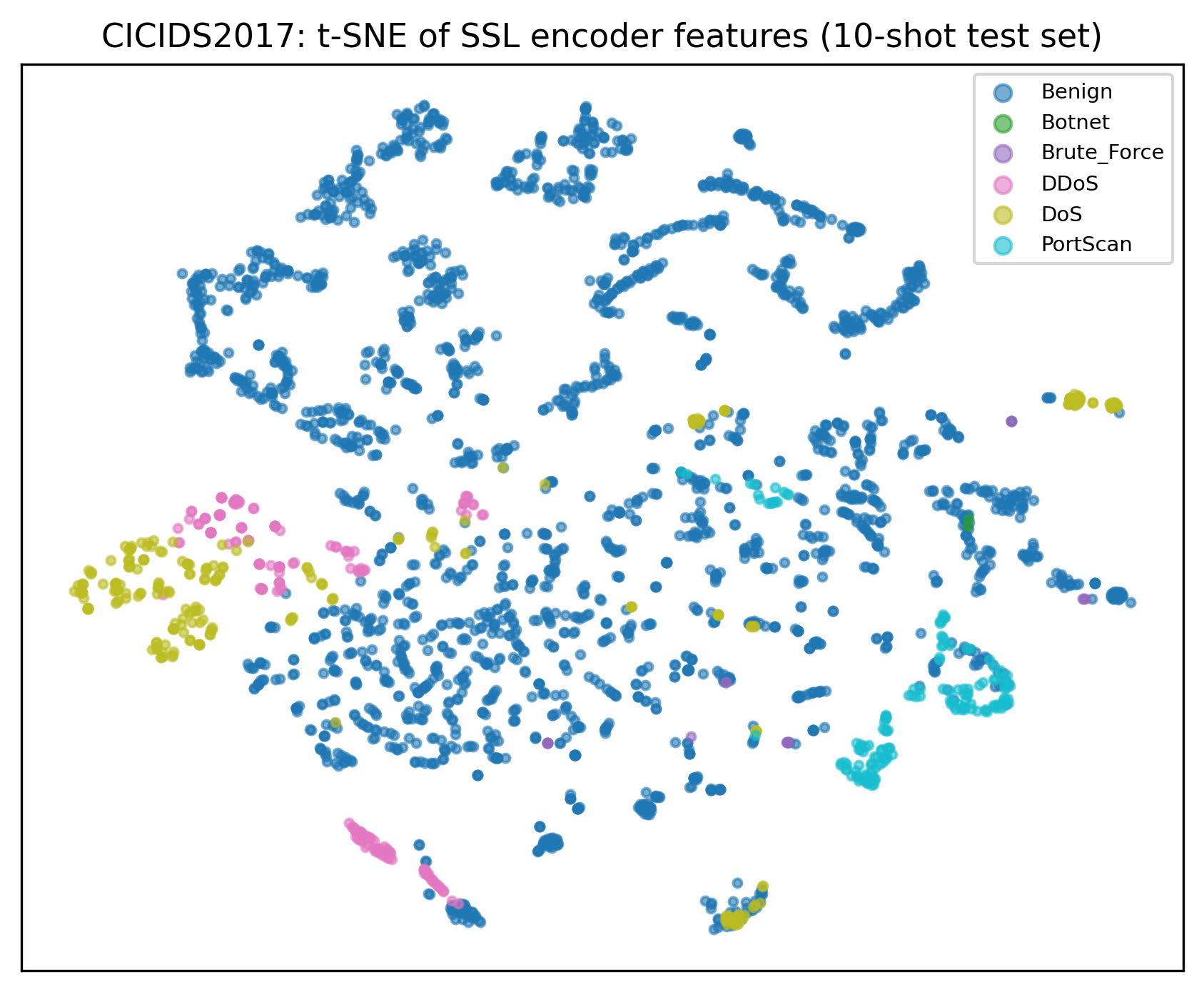
• CICIDS2017 深入分析:per-class F1 对比、混淆矩阵、t-SNE 特征可视化
• 优化 FlowFeatureEncoder(SimCLR-style 自监督预训练),标签合并策略(15→7 类)
2. 论文内容完善
• 引言强化:新增"研究动机"段落,明确指出"预训练表征覆盖盲区"这一核心 gap,以及检索增强在加密流量少样本分类中尚未被系统性验证的研究空白
• 贡献强化:补充"据我们所知首次"的定位声明,新增核心发现(检索增强收益与预训练覆盖缺口成正比),使贡献更具指导意义
• 新增 Macro-F1 主结果表(补充 Accuracy 表),补充 CICIDS2017 深入分析(per-class F1、混淆矩阵、t-SNE)
• 新增伪代码 Algorithm 1(RAC-ET 训练与推理流程)
• 相关工作新增与 kNN 的本质区别段落(三个维度:非参数 vs 参数化融合、噪声抑制、端到端优化)
• 补充 NIDS 综述引用,关键词补充"入侵检测"
• 修复图表浮动位置问题(placeins + FloatBarrier)
3. 英文版本
• 全文翻译(27 页),保持公式/表格/图注/伪代码/引用完全一致
• 润色优化:拆分长句、被动语态调整为主动语态
• 提供 PDF + Word + LaTeX 三种格式
4. 代码仓库更新
• CICIDS2017 实验脚本和结果已推送到 GitHub
• README.md 完全重写,包含三个数据集的完整结果
5. 创新点强化
• 实验方案覆盖少样本与全样本场景,消融实验分析检索规模 K、残差连接等关键设计
• 讨论新增:"动态知识库更新与零成本适配"段落 — 新样本即插即用,无需重训任何模块
6. 导师审阅后修订(最新 2026-04-22)
• 摘要:按导师审阅格式重写 — 精炼表述,用真实实验数据(CICIDS2017 平均+6.72%,IoT-23 平均+20.09%/最大+28.15%,CSTNET 全量91.75% +3.0%)
• 关键词:更新为"加密流量分类;少样本学习;检索增强分类;预训练模型;网络安全"
• 引言:按导师格式调整 — 报告引用改为 Imperva/FBI 具体出处;三挑战后直接接方法提出(去掉过长的"覆盖盲区"分析段);技术路线补充 DeepPacket、FS-Net 引用
• 贡献:按导师意见精简为3条(去掉 FlowFeatureEncoder 单独条目和第4条),聚焦核心创新
• 相关工作-少样本学习:大幅展开 — Matching Networks/Prototypical Networks/MAML/Adapter/LoRA 每个方法独立描述;新增局限性分析段(元学习依赖辅助任务、支撑样本代表性不足、参数化知识无法动态更新),自然引出检索增强动机
• 相关工作-检索增强:末段改为"借鉴 kNN-LM 非参数记忆增强思路"的表述;加密流量部分改为"现有研究主要集中于特征表示学习,对利用外部相似样本提供辅助上下文讨论较少"
• 英文版:同步更新所有改动
• 所有PDF、Word、LaTeX源码均已更新
7. 待完成项
• 作者/单位/基金号信息(待确认后填写)
• 目标期刊模板适配(待确定期刊后调整)
• AI率检测和降重(学生自行处理)
📄 论文在线阅读 — 左侧可选中文字标红批注,右侧对照PDF原文
导师留言板 — Feedback & Ideas
提交新留言 / Submit Feedback
Downloads
Repository
GitHub — Experiment Code & Results
Complete experiment scripts (CSTNET, IoT-23, CICIDS2017), model definitions, and result JSON files.
View on GitHub